Research Data
Before we started collecting data, we asked teachers for guidance. The team at the University of Leeds are very familiar with schools through their own teaching experience, and through our teacher education and leadership work, but we knew that we needed guidance from class teachers and school leaders with current, hands-on practitioner knowledge.
We collected corpus data and interview data for the project. We collected our corpus data in the school year of 2018- 2019, from all 13 of our partner schools. The data consist of written and spoken texts from five subjects: English, mathematics, science, history and geography. At GCSE, these subjects comprise the English baccalaureate (Ebacc), which we took as a proxy for subjects that are considered to be ‘core’. The Ebacc also includes a modern language, but schools aim to teach in the target language, which would make the data complicated for an all-English corpus. We consulted the DfE national curriculum documents for each subject. We interviewed school students and teachers at 5 of our primary and 3 of our secondary partner schools. See below for more details of each kind of data.
* Terminology
The term 'word' can have different meanings: the total number of words, as used in the sense 'a 3000 word essay', or the number of different words, as used in the sense 'young children can learn 5 to 10 new words a day'. When we are writing about the total number of words, corpus linguists use the term token. When we are writing about different words, they use the term type. Our corpus currently has around 2.4 million tokens, and a smaller number of types.
Written corpus data
The written corpus
We asked teachers to tell us what sort of written texts students in Years 5-8 are exposed to and have to understand to access the curriculum. These fell into five main groups:
- Teacher presentations, in Powerpoint format
- Worksheets
- Assessment tasks
- Textbooks
- Reading extracts
We asked schools to give us texts used with their classes in Years 5 and 6 (primary schools) and 7 and 8 (secondary schools) in electronic format where possible. In some cases, we had to scan materials, and sometimes buy copies of textbooks. Mostly, teachers provided us with USB sticks with their materials. These sometimes contained near-identical files, and we also found that more than one school used the same resources, so work was needed to delete duplicate files, and to prepare the texts for corpus analysis. Currently, our written corpus consists of 1,962,934 tokens. These are divided into:
- Key stage 2 (primary, Ys 5&6): 784,247
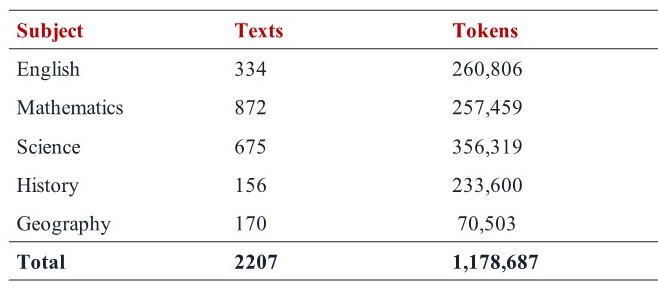
- Key stage 3 (secondary, Ys 7&8): 1,178,687
In KS2, the breakdown by subject is:
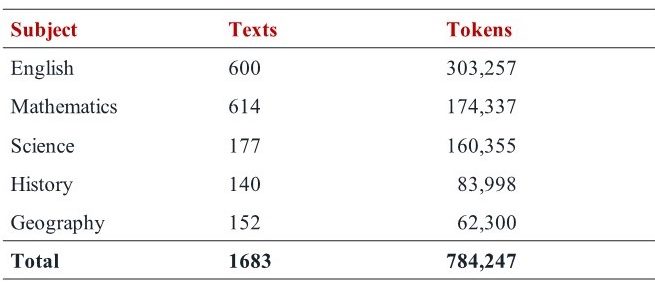
In KS3, the breakdown by subject is:
For more information, please see Chapter 3 of The Linguistic Challenge of the Transition to Secondary School: A Corpus Study of the Academic Language.
Spoken corpus data

© Photo by Oscar Ivan Esquivel Arteaga on Unsplash
We asked teachers in our 13 partner schools to make recordings of themselves teaching in Years 5-8. They used a microphone on a lanyard, which picked up their utterances clearly. We did not transcribe student utterances for two reasons: first, the project is about the language that students encounter, not what they produce, and second, it would have been very difficult to obtain informed consent from all students and their parents or guardians. We have 269 lesson recordings, from 73 different teachers. The recordings are transcribed by an external agency following conventions that we developed. Currently around half of the recordings have been fully transcribed.
At the moment, we have 506, 517 tokens, as follows:
- Key stage 2: 263, 467
- Key stage 3: 243, 050
here is a typical example, from a Year 5 class:
with your partner (.) there’s a few tricky ones on here (.) today (.) okay and don’t worry if you don’t know it this is why we practise it isn't it so that we can go through it again and again (.) who’s got is there anyone’s that’s got ten on one of our SPaG tests ye=yet? (.) okay look only a few very few people in the class (.) so well done if you have (.) but it’s obviously very tricky (.) okay anybody now hasn’t got their partner’s test in front of them ready to mark it? (.) you might have two to mark somebody’s gone (.) gone off somewhere (.) okay this one you should have been able to do I hope which sentence uses a relative clause the map that I brought with me is out of date or the map I bought yesterday is out of date (.) so which one is the relative clause? go on <name M>?#
Here is an example of spoken data from a Year 7 science class:
now remember that forces always act in pairs so what we have (.) is we’ve got the weight acting downwards and we’ve got what we call the reaction force acting upwards (.) okay? so if we have a book which has a weight of four newtons then we draw an arrow (.) okay? now the size of the arrow needs to represent the size of the force keep going (.) okay? so in this case we’re drawing an arrow and the line is four boxes long one two three four and that represents the weight of four (.) now because that book is stationary (.) the opposite force must be acting in the opposite direction and it must be the same size (.) okay? so when we draw that in (.) keep going (.) okay keep going so the reaction force is acting upwards and what do you notice about the size of those arrows? (.) <name F>?#
When the transcriptions are complete, we will do more detailed analysis on teacher talk, comparing it between KS2 and KS3, across subjects, and with written texts.
Interviews with students

Student interviews
We interviewed students from five of our partner primary schools, in focus groups of six students, so a total of 30 students. We talked to them in March and April 2019, when they were in the middle of Year 6, and again in June 2019, after they had taken their KS2 Standard Attainment Tests. We followed them up once they had moved to secondary school. The students' primary schools feed three of our partner secondary schools. We interviewed them in Year 7, in their first term, between October and December 2019. We conducted a fourth interview with two of the five focus groups, in March 2020, but were not able to go ahead with the remaining three groups due to the Covid-19 pandemic and school closure. We have a set of 17 interviews of 35- 40 minutes, which are between 6500 and 9500 words in length. We are currently analysing these.
In Year 6, the students were asked about their feelings about the transition to secondary school, academic study and language. In Year 7, we caught up with how the transition had been for them, and discussed the new academic and linguistic demands of secondary school. Here are some examples of the interview data. All names have been changed.
Interviews with teachers

© Photo by LinkedIn Sales Solutions on Unsplash
Teacher interviews
We interviewed a number of teachers in our partner schools. We currently have six transcribed files, which we are analysing. We asked the teachers about the language challenges of school, and for secondary teachers, of their subject. Here are some examples of the interview data.
For more information, please see Chapter 3 of The Linguistic Challenge of the Transition to Secondary School: A Corpus Study of the Academic Language.